Introduction to Cortex API Resources
Introduction to Cortex API Resources
What is a Resource?
Resources are the fundamental elements of the Cortex API. Each resource is responsible for controlling a specific aspect of e-commerce functionality. For example, the profiles resource is responsible for the customer's details, such as first name, last name, and addresses, while the carts resource is responsible for tracking the items you're purchasing, providing totals on the costs of the items in your cart, and providing a link to the cart's order (see Resource Reference list for a list of the resources and their responsibilities). Cortex API client applications communicate and initiate operations with these resources by sending HTTP GET, PUT, DELETE, and POST requests to them.
What is a subresource?
Some resources, such as profiles, carts, and purchases, have subresources. A subresource contains a subset of the parent resource's responsibilities. For example, the carts resource has a lineitems subresource that list the items a customer added to their cart. Another example is the addresses resource, which is a subresource of profiles. The address resource is responsible for the customer's shipping and billing addresses, while the profile's resource is responsible for the customer's details like first name, last name, and so on. The reason these functionalities are broken up into resources and subresources is two-fold. The first reason is that separating responsibilities into individual resources are how RESTful APIs are designed. In REST, each resource should have the smallest amount of responsibilities so the API's functionalities are as granular as possible. The second reason is extensibility. Some store's may not require customer addresses or the stores may have their own system for maintaining customer addresses, so we've isolated customer addresses into a single subresource that can be easily removed without affecting the rest of the API.
Resource Design Philosophy
The Cortex API is built on an OSGi framework, where each resource in the framework is an OSGi Bundle. The reason why we've chosen OSGi as a framework is because it provides lots of flexibility for developers who are creating new resources as the framework allows you to add new resources without having to perform extensive customizations to wire them in.
Customizing the API
Customizing the Cortex API's functionality is done solely through creating new resources. Even if you are adding a single field to an existing representation, like adding the customer's email address to profiles, you create a new resource to do this. This model is quite different from the Binary-Based Development development model we recommend customers follow when customizing the Elastic Path platform. Binary-Based development focuses on using the classic inheritance model to extend the platform. Cortex API's extension model emphasizes building new resources and relationships to expand the capabilities of your Cortex API. Take a look at the tutorials for examples of how to customize the API by creating new resources, see Tutorials.
Initially, it may seem strange to create a new resource when all you want to do is add a small field to an existing resource. As the Elastic Path platform is an open source platform, naturally developers would want to code directly in the resource they are building the functionality for; however, this is not the recommended practice. Creating new resources to add and modify existing API functionality gives you:
- Simplified Cortex API upgradability - when your customized code is in new resources, you can easily upgrade the API by simply replacing the out-of-the-box resources and not have to worry about your customized code getting rewritten.
- Flexibility upgrading your own customized resources - If your customized code is localized into new resources, they are easier to upgrade than they would be if the code were written in the standard out-of-the-box resources.
How do Resources Work?
After the request passes through the Authentication layer, HTTP Bridge, and the Kernel, the request comes to the resource. The resource accepts the request and, depending if the request was a GET, PUT, POST, or DELETE, runs either a write or lookup operation to read or write data to the Integration layer. The Integration layer then uses a CRUD operation to read or write data to the Commerce Engine. The result of the operation is passed back to the resource in an ExecutionResult that contains a DTO. Because DTOs are generic and may contain more information than required for the operation, the resource transforms the DTO into a representation and then passes the representation back to the Kernel. The Kernel then converts the representation into a JSON object and passed it back to the client application. For an overview of the how the API communicates with the various layers, see Architecture Call Stack.
Resources have many components to facilitate the flow of representations going down into the Integration layer and the flow of DTOs coming back up the stack. The sections below outline some of the major components in resources and describes how they work. Take note that not all resources have these components. Some resources only have writers, while other resources only have lookups.
Lookup and Writers
Resource Lookups and Writers call down into the Integration layer to perform the GET, PUT, POST, or DELETE operation that was initiated by Cortex API client application. Lookups and Writers generally have the same components and follow the same code flows as outlined below. The goal of this section is to give you an idea how the out-of-the-box lookup and writers work, so you can follow these best practices when you code your own resources.
Lookup
When the client application makes a GET request to a resource, the resource uses a lookup to retrieve the data. Lookups use a strategy pattern and a transformer to call down into the Integration layer to perform the read/GET operation. To understand how this works, the following example assumes the Cortex API client application made a GET request to the profiles resource in order to retrieve the logged in client's profile.
In the example, ProfileLookupImpl.java instantiates a ProfileLookupStrategy and a ProfileTransformer. Then the getProfile(String scope, final String profileId) method uses the ProfileTransformer to create a profile DTO with the profileID that the client is trying to GET. Then the ProfileLookupStrategy.find(profileDto) method passes the profile DTO down into the integration layer to retrieve the profile. Once the operation completes, we check if the read was successful using the profileResult.isFailure() method. If the read is successful, the ProfileTransformer converts the profileDTO into a profile representation and then surfaces that back up to the Kernel for processing.
@Singleton
@Named("profileLookup")
public final class ProfileLookupImpl implements ProfileLookup {
private final ProfileLookupStrategy profileLookupStrategy;
private final ProfileTransformer profileTransformer;
/**
* Default constructor.
*
* @param profileLookupStrategy the lookup strategy.
* @param profileTransformer the representation transformer.
*/
@Inject
ProfileLookupImpl(
@Named("profileLookupStrategy")
final ProfileLookupStrategy profileLookupStrategy,
@Named("profileTransformer")
final ProfileTransformer profileTransformer) {
this.profileLookupStrategy = profileLookupStrategy;
this.profileTransformer = profileTransformer;
}
@Override
public ExecutionResult<ProfileRepresentation> getProfile(final String scope, final String profileId) {
final ExecutionResult<ProfileRepresentation> result;
ProfileDto profileDto = profileTransformer.transformToDto(scope, profileId, null);
ExecutionResult<ProfileDto> profileResult = profileLookupStrategy.find(profileDto);
if (profileResult.isFailure()) {
result = ExecutionResultFactory.createErrorFromExecutionResult(profileResult);
} else {
ProfileRepresentation profileRepresentation = profileTransformer.transformToRepresentation(scope, profileResult.getData());
result = ExecutionResultFactory.createReadOK(profileRepresentation);
}
return result;
}
} Writer
When a client application makes a PUT, POST, or DELETE request to a resource, the resource's writer is used to perform the operation. Writers use a strategy pattern to call down into the Integration layer to perform the create, update, or delete operation. To understand how this works, the following example assumes the Cortex API client application made a PUT request to the profiles resource to update the logged in client's profile.
In the example, ProfileWriter instantiates a ProfileWriterStrategy and a ProfileTransformer. Then the ProfileWriter.update(String profileId, ProfileRepresentation profile) method receives the ProfileRepresentation and the profileId. In this case, the ProfileRepresentation is the updated profile that we want to write to the Commerce Engine and the profileId is the ID of the profile we want to update. Continuing with the code flow, we see that ProfileRepresentation is converted into a ProfileMutator and the profileID is set to it. Then the ProfileTransformer converts the ProfileMutator into a ProfileDTO (for why we convert this into a DTO, see Why Use Transformers and DTOs?). The ProfileWriterStrategy then calls down to the Integration layer with the ProfileDTO to update. The Intergration layer writes the ProfileDTO to the Commerce Engine and the result is returned as an ExecutionResult, which then surfaces back up to the Kernel for processing.
@Named("profileWriter")
public final class ProfileWriterImpl implements ProfileWriter {
private final ProfileWriterStrategy profileWriterStrategy;
private final ProfileTransformer profileTransformer;
/**
* The default constructor.
*
* @param profileWriterStrategy the writer strategy.
* @param profileTransformer the transformer.
*/
@Inject
ProfileWriterImpl(
@Named("profileWriterStrategy")
final ProfileWriterStrategy profileWriterStrategy,
@Named("profileTransformer")
final ProfileTransformer profileTransformer) {
this.profileWriterStrategy = profileWriterStrategy;
this.profileTransformer = profileTransformer;
}
@Override
public ExecutionResult<Void> update(final String profileId, final ProfileRepresentation profile) {
final ExecutionResult<Void> result;
ProfileMutator profileMutator = ProfileMutator.create(profile);
profileMutator.setProfileId(profileId);
ProfileDto profileDto = profileTransformer.transformToDto(profileMutator.getRepresentation());
ExecutionResult<Void> profileUpdateResult = profileWriterStrategy.update(profileDto);
if (profileUpdateResult.isSuccessful()) {
result = ExecutionResultFactory.createUpdateOK();
} else {
result = ExecutionResultFactory.createErrorFromExecutionResult(profileUpdateResult);
}
return result;
}
} Basically, because it simplifies programming. Breaking up the resource's responsibilities into separate classes makes it easier to code.
You'll notice the lookups and writers use strategies. The strategy's interface is defined in the Rest Resource layer, while its implementation is defined in the Integration layer. This provides loose coupling between the Rest Resource layer and the Integration layer. With this setup, the resource defines what it needs through the strategy and then how that information is retrieved is defined in the Integration layer. This way the code in the Integration layer can be changed without having to refactor the resource in the Rest Resource layer.
Transformers and Mutators
Requests contain representations. The Integration layer doesn't understand representations, it understands DTOs. Conversely, the layers above the Integration layer, Rest Resources and RelOS, don't understand DTOs, they understand representations. Transformers and mutators convert representations into DTOs and convert DTOs back into representation so requests can drill down through Cortex API layers and DTO responses can percolate back up through the layers.
Transformer
When the request originates from the Kernel, transformers are used to convert the representation into a DTO. When the request's response comes back from the Integration layer, the transformer converts the DTO into a representation. The ProfileTransformer shown below is a good example of a simple transformer. Usually, transformers have these basic methods:
- transformToDto(ProfileRepresentation representation)Receives the representation as a parameter, converts it into a DTO, and then returns the DTO. http://sitedocs.elasticpath.com/JavaDocs/rest-resources/1.9.0/com/elasticpath/rest/resource/profiles/transform/ProfileTransformer.html
- transformToRepresentation(ProfileDto profileDto)Receives the DTO as a parameter, creates a profile mutator, takes the DTOs values and sets them to the profile mutator, then returns a profile representation.
@Named("profileTransformer")
public class ProfileTransformer {
/**
* transforms a profile entity to a representation.
*
* @param profileDto the profile entity.
* @return the profile representation.
*/
public ProfileRepresentation transformToRepresentation(final ProfileDto profileDto) {
ProfileMutator profileMutator = ProfileMutator.create();
String encodedProfileId = Base32Util.encode(profileDto.getUserGuid());
profileMutator
.setScope(profileDto.getScope())
.setProfileId(encodedProfileId)
.setFirstName(profileDto.getFirstName())
.setLastName(profileDto.getLastName());
return profileMutator.getRepresentation();
}
/**
* Transforms a profile representation into a profile DTO.
*
* @param representation the profile representation.
* @return the profile DTO.
*/
public ProfileDto transformToDto(final ProfileRepresentation representation) {
ProfileDto profileDto = ResourceTypeFactory.createResourceEntity(ProfileDto.class);
String profileId = representation.getProfileId();
if (profileId != null) {
profileId = Base32Util.decode(profileId);
}
profileDto.setFirstName(representation.getFirstName())
.setLastName(representation.getLastName())
.setPassword(representation.getPassword())
.setScope(representation.getScope())
.setUserGuid(profileId);
return profileDto;
}
/**
* Creates a profileDto with the given fields, and decodes the profile ID.
*
* @param scope the scope.
* @param profileId the profile ID.
* @param username the username.
* @return the profile DTO.
*/
public ProfileDto transformToDto(final String scope, final String profileId, final String username) {
ProfileDto profileDto = ResourceTypeFactory.createResourceEntity(ProfileDto.class);
String decodedProfileId = Base32Util.decode(profileId);
profileDto.setUserGuid(decodedProfileId)
.setScope(scope)
.setUsername(username);
return profileDto;
}
} Mutator
Mutators modify and create representations (for why we use mutators to do this, see Why use Transformers, Mutators, and DTOs?). From the ProfileMutator example below, we can see that the mutator extends the RepresentationMutator class and is typed to the ProfileRepresentation. The mutator has a number of set methods to define the representation's values.
public final class ProfileMutator extends RepresentationMutator<ProfileRepresentation> {
/**
* Creates a new instance of ProfileMutator. This also creates the Profile representation inside.
*
* @return the new ProfileMutator
*/
public static ProfileMutator create() {
return create(ResourceTypeFactory.createRepresentation(ProfileRepresentation.class));
}
/**
* Creates a new instance of ProfileMutator for a provided representation.
* @param profileRepresentation the profile Representation.
* @return the new ProfileMutator
*/
public static ProfileMutator create(final ProfileRepresentation profileRepresentation) {
return new ProfileMutator(profileRepresentation);
}
private ProfileMutator(final ProfileRepresentation representation) {
super(representation);
}
/**
* @param firstName the given name to set
* @return This ProfileMutator instance
*/
public ProfileMutator setFirstName(final String firstName) {
set(ProfileRepresentation.GIVEN_NAME, firstName);
return this;
}
/**
* @param lastName the family name to set
* @return This ProfileMutator instance
*/
public ProfileMutator setLastName(final String lastName) {
set(ProfileRepresentation.FAMILY_NAME, lastName);
return this;
}
/**
*
* @param password the password to set.
* @return This ProfileMutator instance.
*/
public ProfileMutator setPassword(final String password) {
set(ProfileRepresentation.PASSWORD, password);
return this;
}
/**
* @param profileId the profile ID to set
* @return This ProfileMutator instance
*/
public ProfileMutator setProfileId(final String profileId) {
set("profileId", profileId);
return this;
}
/**
* @param scope the scope
* @return This ProfileMutator instance
*/
@Internal
public ProfileMutator setScope(final String scope) {
set("scope", scope);
return this;
}
}
Why use Transformers, Mutators, and DTOs?
The Integration layer is designed so other backend systems—systems other than the Elastic Path Commerce Engine—can integrate with Cortex API. Most backend systems, including ours, don't understand representations. However, pretty much all backend systems, including ours, understand DTOs. Therefore, the Integration layer communicates with backend systems using DTOs. The layers above the Integration layer communicate using representations. Transformers and mutators convert DTOs to representations and representations to DTOs, so that Cortex API can communicate with different backend systems, not just Elastic Path's.
Representations are immutable, which means their state can't change once they are created (by state we mean the representation's values). Representations are designed this way because, as a coding practice, using immutable objects leads to simple and reliable code, thread-safety, and restrict accidental changes to the representation's state. Because representations can't be changed directly, mutators are used to modify them at the Rest Resource layer. By having to code a mutator to change a representation, the chances of a developer accidentally making changes to a representation is reduced.
Representations
RESTful APIs communicate by passing representation between the Cortex API client application and the backend system. Representations are a document that captures the current or intended state of a resource.
On the Cortex API client developer side, representations are JSON objects. When a client application GETs the logged in customer's profile, the profile representation, shown below, returns and shows the current state of the resource. Earlier we said representations can also capture the intended state of a resource. What this means is that if the client application were POSTing the representation below to create or update a profile, then this JSON object would be the intended state of the representation.
Example of a JSON Object representation:
{
"self": {
"type": "application/vnd.elasticpath.profile",
"uri": "/commerce-legacy/profiles/<storeid>/default",
"href": "http://www.onlinstore.com/profiles/<storeid>/default",
"max-age": 0
},
"links": [
{
"type": "application/vnd.elasticpath.links",
"rel": "purchases",
"href": "http://www.onlinstore.com/purchases/<storeid>",
"uri": "/commerce-legacy/purchases/<storeid>"
},
{
"type": "application/vnd.elasticpath.links",
"rel": "addresses",
"rev": "profile",
"href": "http://www.onlinstore.com/profiles/<storeid>/default/addresses",
"uri": "/commerce-legacy/profiles/<storeid>/default/addresses"
},
{
"type": "application/vnd.elasticpath.links",
"rel": "paymentmethods",
"rev": "profile",
"href": "http://www.onlinstore.com/paymentmethods/<storeid>",
"uri": "/commerce-legacy/paymentmethods/<storeid>"
}
],
"family-name": "Harris",
"given-name": "Oliver",
"username": "oliver.harris@elasticpath.com"
}
Example of the Cortex API's java code side representation:
public interface ProfileRepresentation extends Representation {
/** MIME type. */
String TYPE = "application/vnd.elasticpath.profile";
/**
* @return The given name.
*/
@Property(name = ProfileRepresentationPropertyNames.GIVEN_NAME)
String getFirstName();
/**
* @return The family name.
*/
@Property(name = ProfileRepresentationPropertyNames.FAMILY_NAME)
String getLastName();
/**
* @return the password value.
*/
@Property(name = ProfileRepresentationPropertyNames.PASSWORD)
String getPassword();
/**
* @return The profile id.
*/
@Internal
String getProfileId();
/**
* The scope for the profile.
*
* @return The scope.
*/
@Internal
String getScope();
}
How does the Linking Strategy Work?
Cortex API is a REST Level 3 API, which means it follows the HATEOAS architecture design constraint. As required by HATEOAS, a resource representation contains links to other related resources. For example, the profiles representation has links to addresses, purchases, and paymentmethods, all of which are related to the profiles resource (see GET - a profile for this example). By following the links provided in the profiles resource, customers can view their addresses, paymentmethods, and purchases.
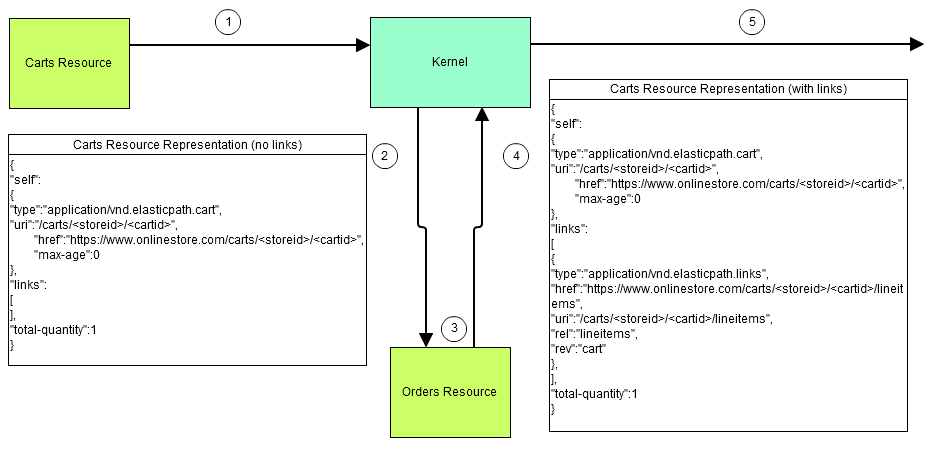
Resource representation are constructed during the linking phase. During this phase, the resource is built into a representation and the links to related resources are attached to the representation. The workflow below describes this process:
- The carts resource sends its representation to Cortex API kernel
- Cortex API kernel sends the representation to all other resources.
- If the proper link strategy exists, a resource inserts a link to itself in the representation.
- The resource sends the representation back to Cortex API kernel
- After all resources inserted their links, Cortex API kernel converts the representation into a JSON object and sends it to the client.
Link Strategy Development Design
When you are creating a new resource that will contain links to other resources, keep in mind the Cortex API's secret admirer rule when implementing your link strategies. The secret admirer rule means the resource being linked to doesn't know about the resource linking to it. For example, in Tutorial 2 - ExtensionProfile you create an extension that attaches a link to the profiles resource. The extension project's link strategy follows the secret admirer rule because the profiles resource does not know about the extension project, but the extension project knows about the profiles resource and attaches a link to it. The reason the API was designed with this rule in mind is extensibility. This way when you add a new resource you don't need to update all the existing resources to be aware of the new resource.
Take a look at Tutorial 2 - ExtensionProfile for an example of implementing resource's link strategy.