Inspecting Solr Indexes with Luke
Inspecting Solr Indexes with Luke
Solr is built on Lucene, which means you can use the Lucene index viewer, Luke, to view our Solr indexes. This can be useful for checking the contents of an index, making sure a field is indexed as expected, for example.
You can download lukeall-x.x.x.jar (non-standalone version) from http://code.google.com/p/luke/.
Before you start Luke, make sure the luke and lucene-core jars are on the classpath. Use the lucene-core jar in your Maven repository.
The lucene-core jar must appear on the classpath before Luke.
java -classpath $HOME/.m2/repository/apache/lucene/lucene-core/2.3.575780-6.0/lucene-core-2.3.575780-6.0.jar: \ luke-0.7.1.jar org.getopt.luke.Luke
java -classpath C:\Documents and Settings\<username>\.m2\repository\org\apache\lucene\lucene-core\ ^ lucene-core-2.3.575780-6.0.jar;lukeall-1.0.1.jar org.getopt.luke.Luke
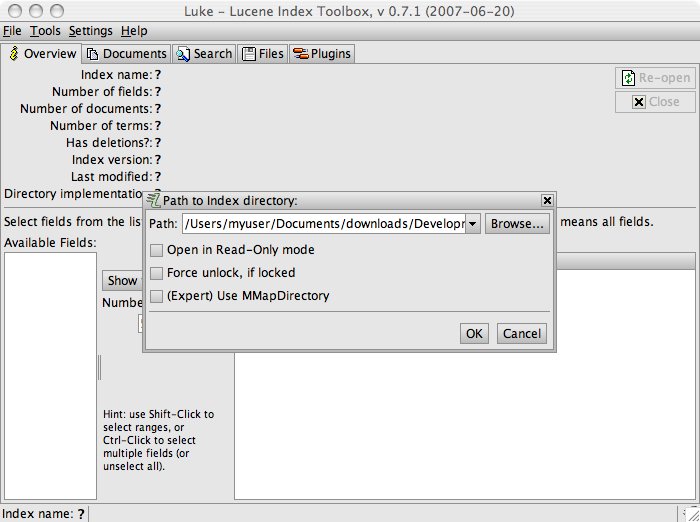
Locate the directory that contains the index. The index directories are normally located under the search server's WEB-INF/solrHome/data directory.
If you get an error message that says, "Invalid path, or not a Lucene index.", check that there is actually data that was indexed (ie. you have added customers in your system before trying to open the customer index). A directory that has a Lucene index will contain the files segments.gen and segments_ [X], as well as other files with the extensions .fdt, .fdx, .fnm, .frq, .nrm, .prx, .tii and .tis.
Generally, the indexes do not store very much human-readable information. Solr only needs to analyze specific information in each object (generally a UID and/or a GUID) in order to index it and adding more data to the indexes can lead to performance degradation. To assist with troubleshooting, click the Reconstruct and Edit button to display a version of the current document that has been reconstructed from the document's position in the index. The information may not be 100% identical to the original information, but it does provide useful hints for debugging. Another option is to store additional information in the index itself. You can do this by modifying the indexed object's field configurations in the <index>.schema.xml file. For example, in product.schema.xml, the <fields> element includes the following <field> configurations:
<field name="objectUid" type="slong" indexed="true" stored="true" required="true"/commerce-legacy/> <field name="brandCode" type="code" indexed="true"/commerce-legacy/>
When a product object is added to the index, its objectUid and brandCode fields are both indexed, but only the objectUid is stored in the index. To store the brandCode in the index as well, add the stored attribute with a value of true:
<field name="brandCode" type="code" indexed="true"/commerce-legacy/>
More fields can be added to the index, but for performance reasons, it is recommended that only the minimum number of fields are stored in the index.