Search and Indexing with Solr
Search and Indexing with Solr
Solr is an open source searching scheme based on Lucene (http://lucene.apache.org/). Solr is used by Elastic Path Commerce for building the search indices and searching them. It handles all searching and sorting requests from both Cortex and Commerce Manager. Solr is hosted by the search server web application. It receives HTTP requests from Commerce Manager and Cortex and returns search results as XML documents.
Solr Cores
Each type of search (customers, orders, categories, etc.) has a separate index, and each index is a separate Solr core. Each Solr core must be explicitly specified in the solr.xml file in the solrHome directory. Only one core can be queried at a time, so to query multiple indexes, sequential calls must be made to the Solr server.
Configuration
Most search results and indexing behaviour can be configured via certain System Configuration Settings as documented in Search Settings. Advanced configuration may be made by modifying the Solr index configuration XML files.
Solr's configuration information XML files are located in the /conf directory under the Solr's home directory (under WEB-INF/solrHome in the searchserver web application directory). There are two types of configuration file:
- The schema files (<indexName>.schema.xml), which define the field types and which fields are stored and indexed.
- The configuration files (<indexName>.config.xml), which contain physical search and update handlers as well as default boost values for fields (there are defaults if not specified there).
Spelling Indexes
Each search category can build spelling indexes. The search category can only use spelling indexes if the search criteria inherits from SpellSuggestionSearchCriteria. Spelling indexes are not kept up to date with the search category indexes. Search category indexes must be built before spelling indexes build. Spelling index builds are automatically handled by Quartz jobs after new items are indexed. The criteria for when the spell checking index builds is configurable, see Spell checking index optimization for more information.
Logging
The version of Solr (1.4) currently used with Elastic Path Commerce uses SLF4J (Simple Logging Façade for Java) with Apache log4j. See Logging (Search Server) for more information on configuring Solr logging through the log4j.properties file.
Indexers
Indexers support two types of updates: incremental updates and full rebuilds. In most cases, indexes are built incrementally. Incremental builds run on a Quartz job. To know which objects/UIDs to update, each object's last modified date is checked. The last build dates for the search indexes are stored in the database table. This table is checked every time the quartz job triggers to determine which indexes need to be rebuilt. After an index is rebuilt, the corresponding row in the table is updated with the date and status. Indexes can be rebuilt from within the Commerce Manager. Upon a wipe of Commerce Manager's database or a full rebuild of the webapp, a reindex is automatically triggered.
Multithreaded Pipeline Indexing
Modified or new objects are put into different pipelines to process. For example, if the new or modified objects are Products, the products are put into a product batch that is processed by the product indexing pipeline. If the new or modified objects are CMUser objects, the objects are put into a CMUser batch that is processed by the CMUser indexing pipeline.
Pipeline Details
7 Indexing Pipelines:
- Product
- SKU
- CMUser
- Category
- Customer
- Rule
Each pipeline has 5 stages: Grouping, Loading, Document Creating, Document Publishing, and Final.
The basic indexing building process is:
- The database is checked for modifications
- If modifications exist, the modified object UIDs are retrieved and put into a lists of either product uids, SKU uids, CMUser uids, category uids, customer uids, or rule uids. The lists are handed to the first stage of the index pipelining
- Pipeline Stage 1: Grouping - The pipeline receives the set of uids. The set is broken into smaller sets of uids and then handed to the loading tasks.
- Pipeline Stage 2: Loading - The loading stage iterates through the sets, retrieves the uid objects from the database, and turns them into java entities.
- Pipeline Stage 3: Document Creating - The loaded entities are sent to the Solr document creation process.
- Pipeline Stage 4: Document Publishing - The created documents are sent to the SolrDocumentPublisher, which publishes the documents to the server
- Pipeline Stage 5: Final - The final stage updates the Pipeline status to be complete
- The index build listeners are notified and the TINDEXBUILDSTATUS database table is updated with the index build status.
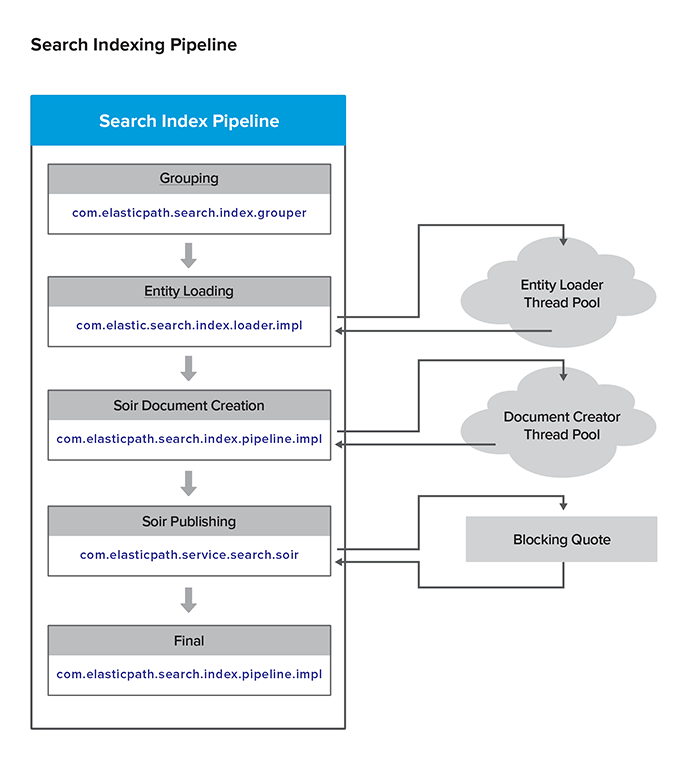
A modification event can either be from these last modified dates explained above or from a notification. On top of that, these can either be additions, modifications or deletions. Deletions always happen last so that if an object is both marked for update and deletion, it will be correctly deleted. This can also be seen as a limitation of the system as you if you wanted to "undo" the process, you can't do it immediately, you would have to wait until after the item has been deleted.
Index Tuning
You can tune the index pipelines to fit your Elastic Path implementation by changing the properties for the following, beans, java files, and tasks. See the following sections for information on:
- How to Change the Index Thread Pool Size
- How to Change the Number of Threads Dedicated to Creating SolrInputDocuments
- How to Change the Schedule for Polling Pipeline Status
- How to Change the Number of UIDs to Fetch from the Database
- Only knowledgeable programmers should change the default bean values. Serious issues can occur if you adjust the bean properties to values your system cannot support.
- When tuning threads, you must make sure your database can support the number of connection required for the search server.
How to Change the Index Thread Pool Size
entityLoaderTaskExecutor Bean This bean is a ThreadPoolTaskExecutor, which controls the indexing pool size.
<!-- This pool is shared among all pipelines for loading entities from the database. Assume that each thread uses at least one database connection, so if set too high it can run the database connection pool dry. (5-10 is default pool-size) --> <bean id="entityLoaderTaskExecutor" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor"> <property name="daemon" value="true" /> <property name="corePoolSize" value="5" /> <property name="maxPoolSize" value="10" /> <property name="keepAliveSeconds" value="600" /> <property name="queueCapacity" value="200000" /> <property name="rejectedExecutionHandler"> <bean class="java.util.concurrent.ThreadPoolExecutor.CallerRunsPolicy" /> </property> </bean>
| Property | Definition |
|---|---|
| maxPoolSize | Sets the maximum number of threads that can be in the thread pool. |
| corePoolSize | Sets the minimum number of threads that will always exist in the thread pool. |
| keepAliveSeconds | Sets the number of seconds, defined in milliseconds, to keep the thread alive for after it has become idle or has completed its task. |
| queueCapacity | Sets the maximum number of objects that can be put into the queue. |
How to Change the Number of Threads Dedicated to Creating SolrInputDocuments
documentCreatorTaskExecutor Bean This bean controls the total number of threads dedicated to creating SolrInputDocuments.
<!-- This pool is shared among all pipelines for the DocumentCreatingStage. This stage is also entitled to use the database (16-25 is default pool-size) --> <bean id="documentCreatorTaskExecutor" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor"> <property name="daemon" value="true" /> <property name="corePoolSize" value="25" /> <property name="maxPoolSize" value="25" /> <property name="keepAliveSeconds" value="600" /> <property name="queueCapacity" value="200000" /> <property name="rejectedExecutionHandler"> <bean class="java.util.concurrent.ThreadPoolExecutor.CallerRunsPolicy" /> </property> </bean>
| Property | Definition |
|---|---|
| maxPoolSize | Sets the maximum number of threads that can be in the thread pool. |
| corePoolSize | Sets the minimum number of threads that will always exist in the thread pool. |
| keepAliveSeconds | Sets the number of seconds, defined in milliseconds, to keep the thread alive for after it has become idle or has completed its task. |
| queueCapacity | Sets the maximum number of objects that can be put into the queue. |
How to Change the Schedule for Polling Pipeline Status
pipelineMonitorScheduler Task This scheduler periodically poles the pipelines' status and updates their status externally.
<task:scheduler id="pipelineMonitorScheduler" pool-size="7" /> <task:scheduled-tasks scheduler="pipelineMonitorScheduler"> <task:scheduled ref="productIndexingPipeline" method="periodicMonitor" fixed-delay="2500" /> <task:scheduled ref="skuIndexingPipeline" method="periodicMonitor" fixed-delay="2500" /> <task:scheduled ref="cmUserIndexingPipeline" method="periodicMonitor" fixed-delay="2500" /> <task:scheduled ref="categoryIndexingPipeline" method="periodicMonitor" fixed-delay="2500" /> <task:scheduled ref="customerIndexingPipeline" method="periodicMonitor" fixed-delay="2500" /> <task:scheduled ref="ruleIndexingPipeline" method="periodicMonitor" fixed-delay="2500" /> </task:scheduled-tasks>
Each tasks is set to pole the index pipeline every 2.5 seconds. This value is configurable.
How to Change the Number of UIDs to Fetch from the Database
uidGroupingTask.java The property groupSize property in this java file sets the number of uids to fetch from the database in one request. The default if 50. This java file is located at ep-search/src/main/java/com/elasticpath/search/index/grouper/impl/UidGroupingTaskImpl.java
How to Change the Solr Publisher's Queue Size
QueueingSolrDocumentPublisher.java This java file is located at search/ep-search/src/main/java/com/elasticpath/search/index/solr/service/impl/QueueingSolrDocumentPublisher.java This class is responsible for queuing the documents into the Solr publisher. You can configure the queue size by adjusting the following properties.
- DEFAULT_QUEUE_SIZE - Sets the maximum queue size. Default is 1500.
- QUEUE_DRAIN_SIZE - Sets the maximum number of Solr document which will be published to the server at once. Default is 499, which is one less than the maximum size that the thread will pull from the queue at once.
Asynchronous Index Notification
The index subsystem has an asynchronous notification system that can be utilized to notify the indexes of important events. The database is used as a queue, so once notifications are processed, they are not able to be accessed again.
Currently there are three types of notifications:
- General commands
- Specific/container UID matchers
- Index queries
General commands are fairly obvious and affect all objects; they should not require a specific UID or object type to act upon. These, in essence, are special container UID matchers. Generally, this these should only be deletion of all indexes and rebuilding all indexes.
Specific/container UID matchers are where things get complicated. These types of notifications require a UID and object type to process. In the simplest case, the object type is the type the index is working with (or a SINGLE_UNIT entity type). The indexers can also extend this functionality to process a specific entity type (a container or perhaps related UID). For example, the product index can handle the affected UID of a store. This would be a container UID matcher where the indexer knows that this store UID really means all products within the store.
Index queries were created because it is sometimes slow to use direct DB queries for large container UID matchers. These notifications use the index service that we've built to find the desired UIDs. All that's required for this type is search criteria that we use for every other type of search. One thing to note about this type of notification is that because its asynchronous, it may not have the same results that you think it should. For instance, the index could have been updated after you construct the search criteria and your criteria might not cover this new/updated object.
Elastic Path Search Components
Cortex searches and Commerce Manger search are fairly different in regards to what happens under the hood, but they still retrieve results in a unified way. Every type of search has the following general format:
- Create a search criteria for your search (any of the search criteria's can be used)
- Use the IndexSearchServiceto perform the search
- Sends your search criteria to the SolrIndexSearcherImpl
- Passes required information (search configuration and criteria) to the SolrQueryFactoryImpl to construct the SolrQuery
- SolrIndexSearcherImpl then processes the results by reading the UIDs of the results and parses any facet information present in the result set
- SolrIndexSearcherImpl then sends the result back to the client
- Get the results
The SolrQueryFactoryImpl distributes on what type of search you are doing based on the search criteria. Most searches will distribute to the appropriate Query Composer for the construction of the Lucene Query which is used as the Solr Query. This also adds some additional Solr information such as filter queries, number of results, sorting and such. The one special case is the KeywordSearchCriteria. This criteria has no query composer therefore requires the query work to be done elsewhere. This criteria creates a query that sends results to a Solr disjunction max request handler which does the work of constructing the query based on the fields that you give it.
In general, all searches use Solr's ability to page results and perform additional searches as new pages are requested. This allows us to get the objects and forget about them rather than keeping and maintaining a list of objects for each page, especially as the number of results increase.
The Commerce Manager uses a search request job for all searches that it performs. Generally you will be using the request job in one view and a listener listens for results to be returned in another. The request job is passed along with the listener update which should be used in the resulting view. A single reference to the request job should be maintained as the request job handles the changing of search criteria and maintaining of the result set so that a search can be performed again on a different page.
One thing to note about any of the search components (not indexing): they all have locale fallback. For instance, if you search for an item in en_US, you will also be searching for the data in en as well as en_US. This same concept can be seen in search configuration for boost parameters. Boosts can specify a locale of en but can be overriden by values in en_US, or in other words, a search in en_US would fall back to en and finally to no locale if it didn't have any boost values set for en_US or en.
Solr Searching
Solr searching is where the bulk of operations occur. This component is essentially the classes SolrIndexSearcherImpl, SolrQueryFactoryImpl and SolrFacetAdapter. The SolrIndexSearcherImpl distributes the work of building the query to SolrQueryFactoryImpl. It also sends the query off to Solr using the appropriate core for the given search criteria and parses any facet information within the result set.
SolrQueryFactoryImpl is where the construction of the Solr query happens. This construction is generally request handler specific (we have separate construction mechanisms for each of our spell checker request handler, store dismax search and general searches). This class also distributes some of the filter/facet work to SolrFacetAdapter.
Indexing/Searching Utilities
There exists a utility class for performing general functions relating to Solr. For example the IndexUtility class can perform methods to transform an Attribute object into a solr field or provide the ability to sort a list of objects with their respective UID list retrieved from Solr.
Search Criteria
Most search criteria are pretty self explanatory, but there are two which are special: LuceneRawSearchCriteria and FilteredSearchCriteria.
LuceneRawSearchCriteria allows you to harness the full power of the Lucene API very quickly. They are also used in the indexers to reparse query notifications.
FilteredSearchCriteria allow you to not only nest search criteria (even nest a filtered search criteria within itself), but also use a search criteria to filter out results from the original search criteria and AND/OR the results of multiple search criterias. To see the filtered search criteria in action, check out CatalogPromoQueryComposerHelper.
Query Composers
The query composer is the bridge between Elastic Path's search API and the Lucene API. There are many helper methods which allow for easy extension of simple fields, but this doesn't cover all the bases.
All search criteria have a match all flag which overrides any of the parameters in the search criteria.
Debugging Search
The easiest way to debug a search is to send a search directly to the search server yourself through a browser. If JDK logging is set to info or above, Solr will output any query it receives to the log. This query can be taken directly from the log and send to Solr. If you are trying to debug field data, your best bet it to enable storage of all fields and reindex. If you are in need of the fields and don't mind seeing internal data, you can use faceting to reveal these fields for you by using a facet.field query. This isn't always helpful though as it doesn't tell you which document the data came from.
If you are sending manual queries to the server, be sure the server is started and you are sending them to the correct core!
Note that Luke can also be used for debugging when you need to inspect the Lucene indexes.
Query Parser Syntax
The general query parser syntax is:
<field_name>:<query>
The query shouldn't contain any special characters. If special characters are required, they should be escaped using backslashes ( ). If the query contains space, the entire string must be enclosed in double quotes. Queries aren't exactly boolean, but can be translated to booleans:
field1:here && field2:there || field3:back ==> +field1:here +field2:there field3:back
Lucene has the concept of must, must not and could which can be used to construct a boolean query. Combined with brackets, any type of query can be accomplished.
The following query matches all documents:
*:*
Note that EP has modified mixed range queries such that the syntax field:{0 TO *] and field:[0 TO *} are both valid.
For more information on the Lucene query parser syntax, see http://lucene.apache.org/core/old_versioned_docs/versions/3_0_0/queryparsersyntax.html.
Lucene Locks
Lucene locks are bound to happen once in a while during development. The reason that they pop up is because the server was unexpectedly stopped while the indexers were running a job.
To remedy the problem, you have to figure out the index that is complaining, generally this can be seen easily enough in the console. If not, you will have to go into each index directory and search for a file called lucene-*.lck, where the * part is dependent on the machine you are working on. Deleting this file will fix the problem.
The presence of this file should indicate to you that you should reindex, but because the indexers only disregard items after it knows everything has been built, it should pick up these objects again and re-index them.
Reindexing
When possible, rebuild the indexes from Commerce Manager's user interface.
Reindexes can also be triggered by deleting the index data folder, WEB-INF/solrHome/data. Doing so restarts your server from a clean slate, with all index directories repopulating themselves.
Matching Everything
Generally you will have at least 1 criteria to search upon and won't require the match all functionality, but in the case that you do, be aware that this overrides all other queries flags and parameters. Be sure to check for this as it may be the cause of problems if you are using it and forget to clear it.
Add a new field
This tutorial describes how to add a new field to the Solr schema and make it searchable. This involves a few steps:
- Update Solr index schema
- Update the search criteria (optional - generally this is required)
- Update the search criteria query composer
- Update the indexers to index the field (optionally - generally this is required)
- Update ProductFields to expose the new field
Let's add the field Product SKU UID to the product search. First we need to extend the search criteria to store this Product SKU UID.
private Long productSkuUid;
public Long getProductSkuUid() {
return productSkuUid;
}
public void setProductSkuUid(final Long productSkuUid) {
this.productSkuUid = productSkuUid;
}
Now we need to update the Solr index schema. There are many field types that we could use, but let's use a SortableLong.
<fields>
...
<field name="productSkuUid" type="slong" indexed="true" stored="false"/commerce-legacy/>
...
</fields>
Now let's update the product query composer:
public Query composeQueryInternal(...) {
...
hasSomeCriteria |= addWholeFieldToQuery("productSkuUid",
String.valueOf(productSearchCriteria.getProductSkuUid()), null, searchConfig, booleanQuery, Occur.MUST, true);
...
}
public Query composeFuzzyQueryInternal(...) {
...
hasSomeCriteria |= addWholeFuzzyFieldToQuery("productSkuUid",
String.valueOf(productSearchCriteria.getProductSkuUid()), null, searchConfig, booleanQuery, Occur.MUST, true);
...
}
Add the field to the composeFuzzyQueryInternal() method as well. You should be familiar with the addWholeFieldToQuery() method. It is a very helpful helper method in the parent class. It has certain limitations and you may need to create a custom routine like others that are in the class. Now let's update the ProductSolrInputDocumentCreator.java indexer. Add a new method to ProductSolrInputDocumentCreator.java called addSkuUidsToDocument and modify the createDocument() method to call it:
public SolrInputDocument createDocument() {
// ... call our new method to add sku UIDs to the document
addSkuUidsToDocument(solrInputDocument, getEntity());
}
/**
* Adds a product's sku UIDs to the given solr input document.
* @param solrInputDocument the solr input document
* @param product being indexed
*/
protected void addSkuUidsToDocument(final SolrInputDocument solrInputDocument, final Product product) {
if (product.getProductSkus() != null) {
for (ProductSku sku : product.getProductSkus().values()) {
addFieldToDocument(solrInputDocument, SolrIndexConstants.PRODUCT_SKU_UID, String.valueOf(sku.getUidPk()));
}
}
}
At this point Solr will be aware of product SKU UIDs and after re-indexing you should be able to verify that the values are in the index.
- This can be done using the open source tool Luke, a GUI tool that allows browsing Solr indexes.
- Alternatively, you can query the search server directly, e.g.
- http://localhost:8080/searchserver/product/select?q=productSkuUid:123456
Having verified the search server side, we need to expose the new field. To achieve that, we need to modify the private class ProductFields which lives inside SolrQueryFactoryImpl.
private void filterAttributes(final KeywordSearchCriteria searchCriteria, final SearchConfig searchConfig) {
// Add product SKU to search keys
searchKeys.add(SolrIndexConstants.PRODUCT_SKU_UID);
boostValues.add(searchConfig.getBoostValue(SolrIndexConstants.PRODUCT_SKU_UID));
}
Add a new Sort By field
This tutorial describes how to add a new sort field for products. We will create a customization to allow sorting products by UID. First we need to define the new sort type:
public class StandardSortBy extends AbstractExtensibleEnum<SortBy> implements SortBy {
/** Ordinal constant for object UID. */
public static final int OBJECT_UID_ORDINAL = ...; // Increment the value of the greatest constant already defined
/** Object UID. */
public static final SortBy OBJECT_UID = new StandardSortBy(OBJECT_UID_ORDINAL, "OBJECT_UID", "objectUid");
}
Next we need to add the new sort field to the switch statement in SolrQueryFactoryImpl. Remember that sorting is simply an additional field on the SolrQuery. There is already a method that applies the sort field to Solr, so we just need to add it:
private String getSortTypeField(final SearchCriteria searchCriteria) {
switch (searchCriteria.getSortingType().getOrdinal()) {
// ... add the new sort field
case StandardSortBy.OBJECT_UID_ORDINAL:
return SolrIndexConstants.OBJECT_UID;
}
}
The above will translate to a Solr query with the sort parameter set to objectUid in ascending or descending order.
As an example, we can query the search server for products that have a brand name "Canon" and order results by UID in descending order:
http://localhost:8080/searchserver/product/select?q=Canon&qf=brandName&sort=objectUid desc&fl=objectUid&qt=dismax
Note that sorting fields is highly dependent on the data is indexed. For instance, sorting on a field that has multiple values or tokenizes the field may produce invalid results. Tokenized fields/Multi-valued fields may sort based on the of lowest/highest of any of the tokens/values.