
Horizontal Database Scaling
Overview
Scaling the database vertically and adding additional Cortex instances is the simplest and most cost-effective way to increase transaction throughput.
Horizontal Database Scaling (HDS) allows an additional increase in transaction throughput by directing read requests to a cluster of read-only replica databases rather than to the primary database. It should be considered only after the limits of vertical database scalability have been reached.
Supported databases
Horizontal Database Scaling can be enabled for any currently supported database types that support read-only replicas.
However, we have only tested Horizontal Database Scaling on AWS MySQL Aurora and AWS PostgreSQL RDS databases.
note
With regards to PostgreSQL RDS, only version 13.4 and later can be configured with multiple replicas and available read-only cluster/instance endpoint URLs.
Performance characteristics
- The maximum scalability and required number of read replicas depends on the current load. By default one replica is provisioned when deploying MySQL Aurora. More replicas can be added at runtime without service interruption.
- The HDS-enabled application servers (Batch, Search, and Integration) are asynchronous by nature and are not sensitive to replication latency. Typical replication latency, when system is not under load, is 20ms and it could be even shorter, less than 1ms, under high load.
- Our internal performance testing with one primary and one replica database, allowed us to achieve an additional 100 transactions/s with Horizontal Database Scaling enabled.
Architecture changes
Horizontal Database Scaling is supported for the following applications:
- Batch Server
- Search Server
- Integration Server
Scaling a database horizontally means adding additional replica databases for read-only transactions. Each HDS-supported application instance has two data sources: a read/write data source and a read-only data source.
Each data source accesses different endpoints in the Amazon database clusters: an endpoint for the read/write (RW) cluster and an endpoint for the read-only (RO) cluster.
A load balancer distributes read requests to the databases in the read-only cluster. Write requests continue to go to the primary database. The result is higher throughput for user transactions when demand is high.
The following diagram shows an architecture with one primary database and two replica databases.
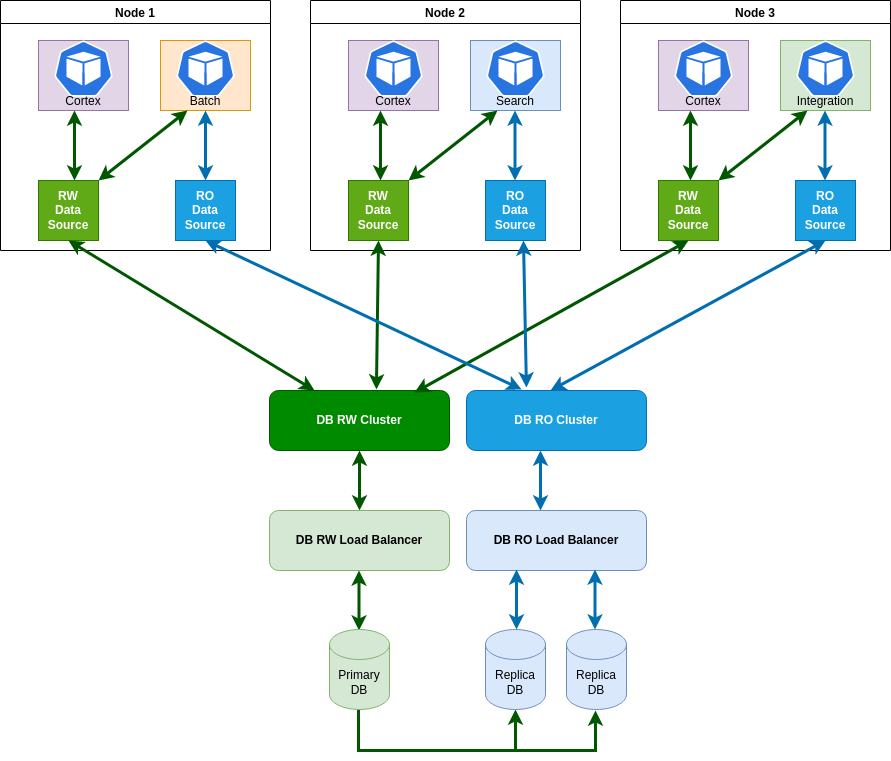
When implementing horizontal database scaling, consider using at minimum two replica databases. The redundancy guarantees high availability in the event that the primary database or a replica database becomes unavailable.
Replication occurs asynchronously as transactions are processed. When a change is made to the primary database, the changes are replicated to the replica databases. Replication lag is very small. In Amazon Aurora, the latency is usually measurable in milliseconds.
Due to asynchronous nature of the HDS-enabled applications, the replication lag doesn't play any role nor affect any service because all relevant data will be eventually processed.
Enabling horizontal database scaling
Horizontal Database Scaling can be configured in many different ways, for all applications or per application.
See Configuring Horizontal Database Scaling support for Self-Managed Commerce on C4K using Elastic Path CloudOps for Kubernetes.