
Horizontal Database Scaling
Overview
Scaling the database vertically and adding additional Cortex instances is the simplest and most cost effective way to increase transaction throughput.
Horizontal database scaling allows an additional increase in transaction throughput by directing read requests to a cluster of read-only replica databases rather than to the master database. It should be considered only after the limits of vertical database scalability have been reached.
note
Please contact your Elastic Path representative if you are considering using horizontal database scaling. The Elastic Path Performance Lab would like to understand your requirements and provide advice on designing and testing your solution.
Supported databases
Horizontal database scaling is supported only for Amazon Aurora MySQL databases.
The architecture is designed to potentially work with any replication-enabled database, but testing has been performed only on Amazon Aurora MySQL. Other databases are not supported at this time.
Performance characteristics
- Reads from replicas may be slightly slower than from the master database because the Java Persistence API L2 cache is disabled for replica databases
- The maximum scalability and required number of read replicas depends on your transaction mix. By default two replicas are provisioned when horizontal database scalability is enabled
- The implementation relies on the exceptional replication speed of Amazon Aurora MySQL databases, which is in the order of milliseconds
Architecture changes
When you scale horizontally, you add additional replica databases for read-only transactions. Each Cortex node has two data sources: a read/write data source and a read-only data source. Each data source accesses different endpoints in the Amazon Aurora database clusters: an endpoint for the read/write (RW) cluster and an endpoint for the read-only (RO) cluster. A load balancer distributes read requests to the databases in the read-only cluster. Write requests continue to go to the master database. The result is higher throughput for user transactions when demand is high.
The following diagram shows an architecture with one master database and two replica databases.
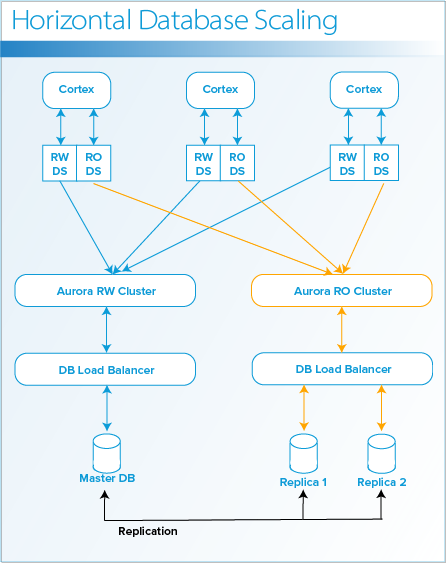
When implementing horizontal database scaling, consider using at minimum two replica databases. The redundancy guarantees high availability in the event that the master database or a replica database becomes unavailable.
Replication occurs asynchronously as transactions are processed. When a change is made to the master database, the changes are replicated to the replica databases. Replication lag is very small. In Amazon Aurora, the lag is measurable in milliseconds.
To minimize potential stale reads, Self-Managed Commerce implements the following changes when horizontal database scaling is enabled:
- Disables the Java Persistence API L2 data cache for replica reads
- Identifies queries that must return results from the master database if related objects have been updated in the current request
Enabling horizontal database scaling
Select the Enable horizontal database scaling check box when deploying an Author/Live environment using Elastic Path CloudOps for Amazon Web Services.